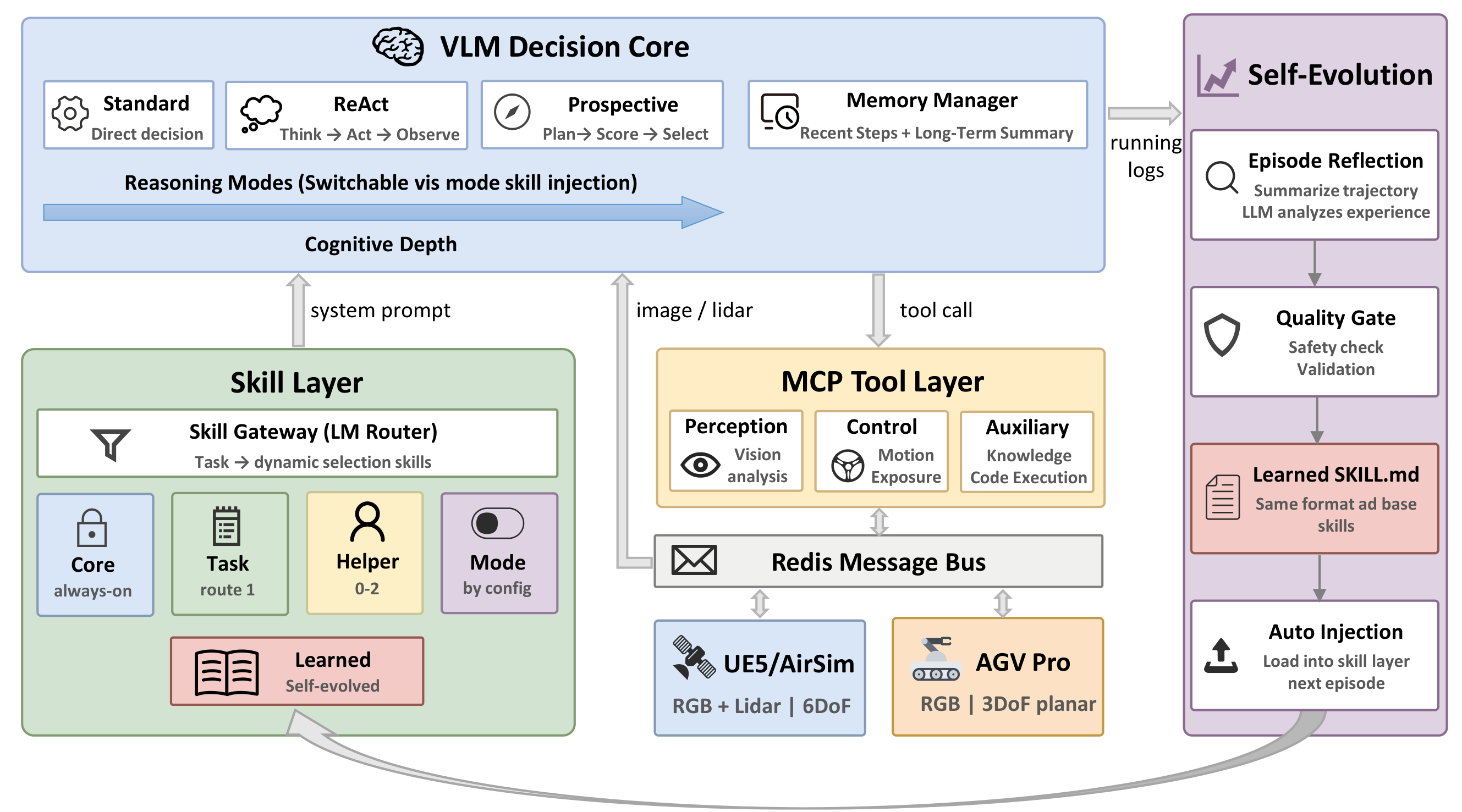
Autonomous on-orbit servicing demands embodied agents that perceive through visual sensors, reason about 3D spatial situations, and execute multi-phase tasks over extended horizons. We present SpaceMind, a modular and self-evolving vision-language model (VLM) agent framework that decomposes knowledge, tools, and reasoning into three independently extensible dimensions: skill modules with dynamic routing, Model Context Protocol (MCP) tools with configurable profiles, and injectable reasoning-mode skills. An MCP-Redis interface layer enables the same codebase to operate across simulation and physical hardware without modification, and a Skill Self-Evolution mechanism distills operational experience into persistent skill files without model fine-tuning.
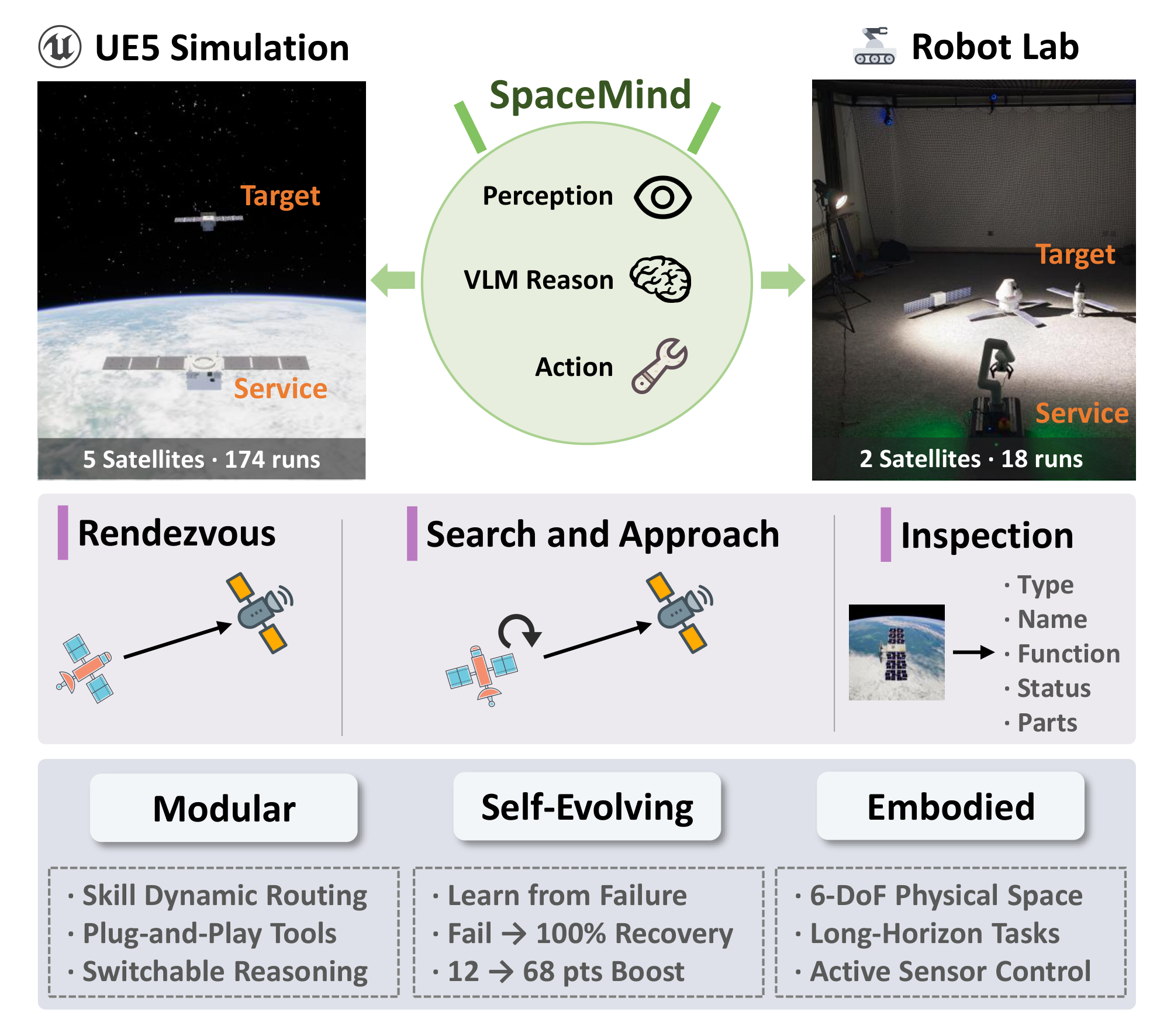
We validate SpaceMind through 192 closed-loop runs across five satellites, three task types, and two environments—a UE5 simulation and a physical laboratory—deliberately including degraded conditions to stress-test robustness. Under nominal conditions all modes achieve 90–100% navigation success; under degradation, the Prospective mode uniquely succeeds in search-and-approach tasks where other modes fail. A self-evolution study shows that the agent recovers from failure in four of six groups from a single failed episode, including complete failure to 100% success and inspection scores improving from 12 to 59 out of 100. Real-world validation confirms zero-code-modification transfer to a physical robot with 100% rendezvous success.